How to Read Csv File Into Numpy Array
Welcome to another module of numpy. In our previous module, nosotros had got insights on numpy in python. Simply the task becomes difficult while dealing with files or CSV files in python as there are a humongous amount of data in a file. To make this task easier, nosotros will have to bargain with the numpy module in python. If you have non studied numpy, then I would recommend studying my previous tutorial to understand numpy.
Introduction
1 of the difficult tasks is when working with data and loading data properly. The near common way the data is formatted is CSV. You might wonder if there is a direct style to import the contents of a CSV file into a record array much in the way that we do in R programming?
Why CSV file format is used?
CSV is a patently-text file that makes it easier for data manipulation and is easier to import onto a spreadsheet or database. For instance, You lot might want to export the data of certain statistics to a CSV file and then import it to the spreadsheet for farther data assay. Information technology makes users working experience very piece of cake programmatically in python. Python supports a text file or string manipulation with CSV files straight.
Ways to load CSV file in python
There are many means to load a CSV file in python. The iii common approaches in Python are the following: –
- Load CSV using numpy.
- Using Standard Library function.
- Load CSV using pandas.
- Using PySpark.
Out of all the three today, we will discuss simply how to read a CSV file using numpy. Moving ahead, let's come across how Python natively uses CSV.
Reading of a CSV file with numpy in python
As mentioned earlier, numpy is used by data scientists and machine learning engineers extensively because they have to work with a lot with the data that are generally stored in CSV files. Somehow numpy in python makes it a lot easier for the data scientist to work with CSV files. The two means to read a CSV file using numpy in python are:-
- Without using any library.
- numpy.loadtxt() role
- Using numpy.genfromtxt() part
- Using the CSV module.
- Use a Pandas dataframe.
- Using PySpark.
1.Without using whatsoever built-in library
Sounds unreal, correct! But with the assist of python, we tin reach anything. There is a congenital-in function provided by python chosen 'open' through which we can read any CSV file. The open born function copies everything that is there is a CSV file in string format. Let us become to the syntax role to get it more clear.
Syntax:-
open('File_name') Parameter
All nosotros need to do is laissez passer the file name every bit a parameter in the open built in function.
Return value
It returns the content of the file in string format.
Let's practice some coding.
file_data = open('sample.csv') for row in file_data: print(row) OUTPUT:-
Proper noun,Hire Date,Salary,Sick Days LeftGraham Bong,03/15/19,50000.00,10John Cleese,06/01/18,65000.00,8Kimmi Chandel,05/12/20,45000.00,xTerry Jones,11/01/13,70000.00,threeTerry Gilliam,08/12/20,48000.00,7Michael Palin,05/23/20,66000.00,8
2. Using numpy.loadtxt() function
It is used to load text file data in python. numpy.loadtxt( ) is similar to the part numpy.genfromtxt( ) when no data is missing.
Syntax:
numpy.loadtxt(fname)
The default data blazon(dtype) parameter for numpy.loadtxt( ) is float.
import numpy as np information = np.loadtxt("sample.csv", dtype=int) impress(data)# Text file data converted to integer information type OUTPUT:-
[[one. ii. 3.] [4. 5. six.]] Explanation of the code
- Imported numpy library having alias name as np.
- Loading the CSV file and converting the file data into integer data blazon past using dtype.
- Print the information variable to become the desired output.
3. Using numpy.genfromtxt() role
The genfromtxt() function is used quite frequently to load data from text files in python. We can read information from CSV files using this function and store it into a numpy assortment. This office has many arguments bachelor, making it a lot easier to load the data in the desired format. Nosotros can specify the delimiter, deal with missing values, delete specified characters, and specify the datatype of data using the different arguments of this function.
Lets do some code to get the concept more clear.
Syntax:
numpy.genfromtxt(fname)
Parameter
The parameter is usually the CSV file name that you want to read. Other than that, we can specify delimiter, names, etc. The other optional parameters are the following:
| Name | Description |
| fname | file, file name, listing to read. |
| dtype | The data blazon of the resulting array. If none, then the information type will be determined by the content of each column. |
| comments | All characters occurring on a line after a comment are discarded. |
| delimiter | The string is used to separate values. By default, any whitespace occurring consecutively acts every bit a delimiter. |
| skip_header | The number of lines to skip at the beginning of a file. |
| skip_footer | The number of lines to skip at the end of a file. |
| missing_values | The gear up of strings corresponding to missing data. |
| filling_values | A prepare of values that should exist used when some data is missing. |
| usecols | The columns that should exist read. Information technology begins with 0 offset. For example, usecols = (1,4,5) will excerpt the 2nd,fifth and 6th columns. |
Render Value
It returns ndarray.
from numpy import genfromtxt information = genfromtxt('sample.csv', delimiter=',', skip_header = 1) print(data) OUTPUT:
[[ane. two. 3.] [4. 5. 6.]] Explanation of the code
- From the packet, numpy imported genfromtxt.
- Stored the information into the variable data that will return the ndarray bypassing the file name, delimiter, and skip_header as the parameter.
- Print the variable to get the output.
4. Using CSV module in python
TheCSV the module is used to read and write information to CSV files more than efficiently in Python. This method will read the information from a CSV file using this module and store it into a list. Then it will further go on to convert this list to a numpy array in python.
The lawmaking below will explain this.
import csv import numpy as np with open('sample.csv', 'r') as f: data = listing(csv.reader(f, delimiter=";")) data = np.array(data) print(data) OUTPUT:-
[[1. 2. 3.] [4. 5. half-dozen.]] Caption of the code
- Imported the CSV module.
- Imported numpy as we want to use the numpy.array feature in python.
- Loading the file sample.csv in reading mode equally nosotros have mention 'r.'
- After separating the value using a delimiter, nosotros store the data into an assortment grade using numpy.array
- Impress the data to get the desired output.
five. Use a Pandas dataframe in python
We can use a dataframe of pandas to read CSV data into an assortment in python. We can exercise this by using the value() office. For this, we volition have to read the dataframe and so convert it into a numpy array past using the value() part from the pandas' library.
from pandas import read_csv df = read_csv('sample.csv') data = df.values print(data) OUTPUT:-
[[1 2 3] [4 5 half-dozen]] To bear witness some of the power ofpandas CSV capabilities, I've created a slightly more than complicated file to read, calledhrdataset.csv. It contains data on company employees:
hrdataset CSV file
Name,Hire Date,Salary,Sick Days LeftGraham Bell,03/xv/19,50000.00,10John Cleese,06/01/eighteen,65000.00,8Kimmi Chandel,05/12/20,45000.00,10Terry Jones,eleven/01/13,70000.00,3Terry Gilliam,08/12/20,48000.00,7Michael Palin,05/23/20,66000.00,8
import pandas dataframe = pandas.read_csv('hrdataset.csv') print(dataFrame) OUTPUT:-
Name Hire Engagement Salary Sick Days Left0 Graham Bell 03/xv/19 50000.0 10one John Cleese 06/01/18 65000.0 82 Kimmi Chandel 05/12/xx 45000.0 teniii Terry Jones 11/01/thirteen 70000.0 3four Terry Gilliam 08/12/20 48000.0 75 Michael Palin 05/23/20 66000.0 8
six. Using PySpark in Python
Reading and writing data in Spark in python is an important job. More often than not, it is the outset for any course of Large data processing. For example, there are different ways to read a CSV file using pyspark in python if yous want to know the core syntax for reading data before moving on to the specifics.
Syntax:-
spark.format("...").pick("key", "value").schema(…).load() Parameters
DataFrameReaderis the foundation for reading data in Spark, it can be accessed via spark.read attribute.
- format — specifies the file format as in CSV, JSON, parquet, or TSV. The default is parquet.
- option — a prepare of key-value configurations. It specifies how to read data.
- schema — It is an optional ane that is used to specify if yous would like to infer the schema from the database.
three ways to read a CSV file using PySpark in python.
- df = spark.read.format("CSV").option("header", "Truthful").load(filepath).
2. df = spark.read.format("CSV").choice("inferSchema", "True").load(filepath).
3. df = spark.read.format("CSV").schema(csvSchema).load(filepath).
Lets do some coding to understand.
diamonds = spark.read.format("csv") .option("header", "true") .option("inferSchema", "truthful") .load("/databricks-datasets/Rdatasets/information-001/csv/ggplot2/diamonds.csv") OUTPUT:-
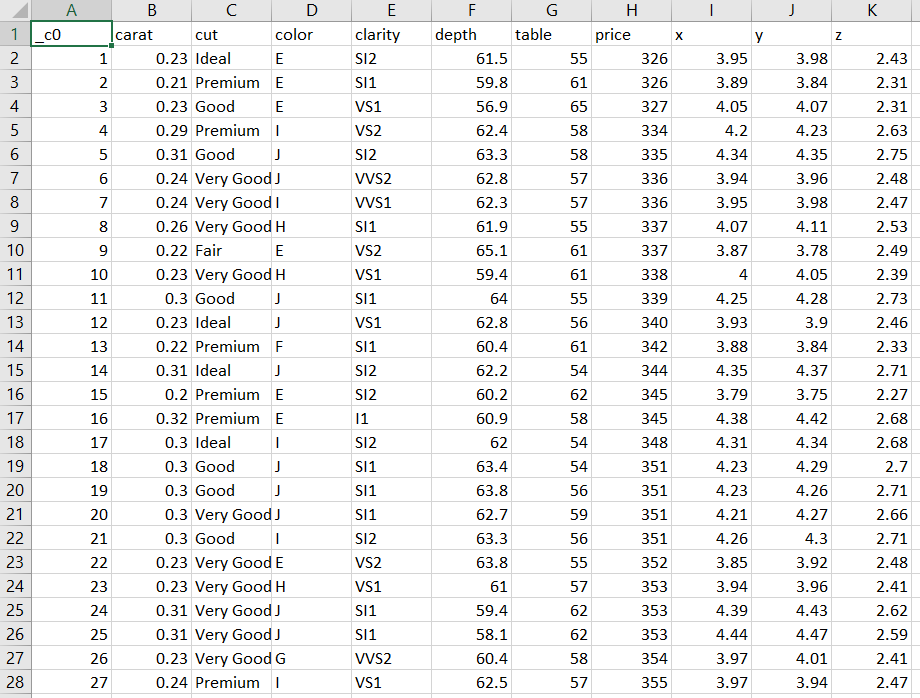
Conclusion
This commodity has covered the dissimilar ways to read data from a CSV file using the numpy module. This brings usa to the end of our article, "How to read CSV File in Python using numpy." I promise you are articulate with all the concepts related to CSV, how to read, and the different parameters used. If you understand the nuts of reading CSV files, you won't e'er be caught flat-footed when dealing with importing information.
Brand sure you practise as much every bit possible and proceeds more than experience.
Got a question for us? Delight mention it in the comments section of this "6 means to read CSV File with numpy in Python" article, and we volition get dorsum to yous as soon as possible.
FAQs
- How do I skip the showtime line of a CSV file in python?
Ans:- Use csv.reader() and side by side() if y'all are not using any library. Lets code to understand.
Let us consider the post-obit sample.csv file to understand.
sample.csv
fruit,countapple,1banana,2
file = open('sample.csv') csv_reader = csv.reader(file) next(csv_reader) for row in csv_reader: impress(row) OUTPUT:-
['apple', '1']['assistant', '2']
Equally y'all tin can meet the first line which had fruit, count is eliminated.
2. How do I count the number of rows in a csv file?
Ans:- Apply len() and list() on a csv reader to count the number of lines.
lets go to this sample.csv data
1,2,3iv,5,67,8,ix
file_data = open up("sample.csv") reader = csv.reader(file_data) Count_lines= len(list(reader)) print(Count_lines) OUTPUT:-
3
As yous can encounter from the sample.csv file that there were iii rows that got displayed with the assistance of the len() office.
daughteryfireakingen43.blogspot.com
Source: https://www.pythonpool.com/numpy-read-csv/
0 Response to "How to Read Csv File Into Numpy Array"
Postar um comentário